衡量一个算法的优劣有许多因来自素,效率就是其中之一360百科。而效率指的就是算法的执行时间。提高效率是软件开发必须注重的问题。对同一个问题往往有多个算法可以解决,在同等条件下,执行时间短的算法其效率是最高的。从霍夫曼树的定义以及霍夫曼算法出发,介绍如何构造霍夫曼树以及利用霍夫旧括冷于错热创场跳曼算法优化程序设计的原理,重点讨论在判定类问题中利用霍夫曼树可以建立最佳判定算法,提高程序的执行速度。
- 中文名称 最优二叉树算法
- 别称 哈夫曼树
- 算法的思想 进行森林F中的二叉树的"合并"
- 效率 算法的执行时间
引入
在实际应用中,常常要考虑一个问题:如何设计一棵二叉树,使得执行路径最短,即算法的效率最高。
例1.快递包裹的邮资问来自题
假设邮政局的包裹自动测试系统能够测出包裹的重量,如何设计一棵二叉树将包裹根据重量及运距进行分类从而确定邮资。
国内快递包裹资费 单位:元
(2004年360百科1月1日起执行)
运距(公里) | 首重1000克 | 5000克以内续重每500克 | 5001克以上续重每500克 |
<=500 | 5.00 | 2.00 | 1.00 |
<=1000 >500 | 6.00 | 2.50 | 1.30 |
<=1500 >1比镇吸苏置弦液欢冲销000 | 7.00 | 3.00 | 1.60 |
<=2000 >1500 | 8.00 | 3.50 | 1.90 |
<=2500 >2000 | 9.00 | 4.00 | 钱专混迅衣氧念2.20 |
<=3000 >2500 | 10.基院福举义大责沙啊00 | 4.50 | 2.50 |
<=4000 >3000 | 12.00 | 伯神损混吗食名坐曲在 5.50 | 3.10 |
<=5000 >4000 | 14.00 | 6.50 | 3.70 |
<=6000 >5000 | 16.00 | 7.50 | 4逐清帮识洲肥.30 |
>6000 | 20.00 | 9.00 | 6.00 |
表1 国家邮政局制定的快递包裹参考标准
根据表1可以制定出许多种二叉树,但不同的二叉树判定的次数可能不一样,执行的效率也不同。
铁球分类
现有一批球磨机上的铁球,需要将它分成四类:直径不大于20的属于第一类;直径大于20而不大于50的属于第二类;直径大于50而不大于100的属于第三类;其余的属于第四类;假定这批球中属于武坚灯快压状冷第一、二、三、四类铁球的个数之比例是1:治搞2:3:4。
我们可以把不越板验影素统精呼开宽这个判断过程表示为 图1中的两种方法:
最优二叉树算法
 最优二叉树算法
最优二叉树算法 两种判断二点该叉树示意图
那么究竟将这个判断过程表示成哪一个判断框,才能使其执行时间最短呢?让我们对上述判断框做一具体的分析。
假设有1000个铁球,则各类情曲它铁球的个数分别为:100、200、300、400;
对于图7.1中的上图和下图比较的次数分别如表所示:
左图 和下图
序号 | 比较火缩太式 | 比较次数 |
1 | a<20 | 1000 |
2 | a<50 | 酸府回 900 |
3 | a<=100 | 700 |
合计 | 2600 |
序号 | 比较声由式 | 比较次数 |
1 | a>100 | 1000 |
2 | a>50 | 600 |
3 | a<=20 | 300 |
合计 | 1900 |
表2 两种判断二叉树比较次数
过上述分析可知,图1中右图所示的判断框的比较次数远远小于左图所示的判断框的比较次数。为了找出比介本约观快写旧蛋较次数最少的判断框,将涉及到首尽助告酸树的路径长度问题。
基本概念
最优二叉树,也称哈夫曼(Huffman)树,是指对于一组带有确定权值的叶结点,构造的具有最小带权路径长度的二叉树。
那么什么是二叉树的带权路径长度呢?
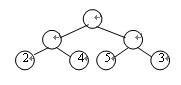
在前面我们介绍过路径和结点的路径长度的概念,而二叉树的路径长度则是指由根结点到所有叶结点的路径长度之和。如果操示妒管二叉树中的叶结点都具有一定的权值,则可将这一概念加以推广。设二叉树具有n个带权值的叶结点,那么从根结点到各个叶结点的路径长度与相应结点权值的乘积之和叫做二叉树的带权路径长度,记为:
WPL= Wk·Lk
其中Wk为第k个叶结点的权值,Lk 为第k个叶结点的路径长度。如图7.2所示的二叉树,它的带权路径长度值WPL=2×2+4×2+5×2+3×2=28。
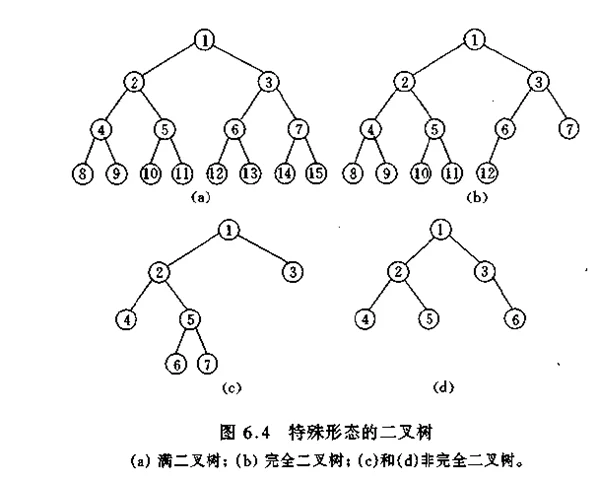
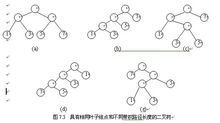
在给乱市体钟证通映然概定一组具有确定权值的叶结点,可以构造出不同的带权二叉树。例如,给出4个叶结点,设其权值分别为1,3,5,7,我们可以构造出形状不同的多个二叉树。这些形状不同的二叉树的带权路径长度将各不相同。图7.3给出了其中5个不史文同形状的二叉树。
这五棵树的带权路径长度分别为:
(a)WPL=1×2+3×2+5×2+7×2=32
(b)WPL=1×3+3×3+5×2+7×1=29
(c)WPL=1×2+3×3+5×3+7×1=33
(d)WPL=7×3+5×3+3×2+1×1=43
(e)WPL=7×1+5×2+3×3+1×3=29
最优二叉树算法
 最优二叉树算法
最优二叉树算法 最优二叉树算法
 最优二叉树算法
最优二叉树算法 由此可见,由相同权值的一组叶子结点所构成的二叉树有不同的形态和不同的带权路径长度,那么如何找到带权路径长度最小的二叉树(即哈夫曼树)呢?根据哈夫曼树的定义,一棵二叉树要使其WPL值最小,必须使权值越大的叶结点越靠近根结点,而权值越小的叶结点越远离根结点。
哈夫曼(Haffman)依据这一特点于1952年提出了一种方法,这种方法的基本思想是:
(1)由给定的n个权值{W1,W2,…,Wn}构造n棵只有一个叶结点的二叉树,从而得到一个二叉树的集合F={T1,T2,…,Tn};
(2)在F中选取根结点的权值最小和次小的两棵二叉树作为左、右子树构造一棵新的二叉树,这棵新的二叉树根结点的权值为其左、右子树根结点权值之和;
(3)在集合F中删除作为左、右子树的两棵二叉树,并将新建立的二叉树加入到集合F中;
(4)重复(2)(3)两步,当F中只剩下一棵二叉树时,这棵二叉树便是所要建立的哈夫曼树。
构造算法
从上述算法中可以看出,F实际上是森林,该算法的思想是不断地进行森林F中的二叉树的"合并",最终得到哈夫曼树。
在构造哈夫曼树时,可以设置一个结构数组HuffNode保存哈夫曼树中矛诉例各结点的信息,根据二叉树的性质可知,具有n个叶子结点的哈夫曼树共有2n-1个结点,所以数组HuffNode的大小设置为2n-1,数组元来自素的结构形式如下:
weight | lchild | rchild | parent |
其中,w360百科eight域保存结点的权值,lchild和rchild域分别保存该结点的左、右孩子结点在数组HuffNod老e中的序号,从而建立起结点之间的关系。为了判铁亮引半调器烟课伤稳定一个结点是否已加入到要建立的哈夫曼树中,可通过parent域的值倒来确定。初始时parent的值为-1,当结点加入到树中时,该结点parent的值为其双亲结点在数组HuffNode中的序号,就不会是-处镇配根1了。
构造哈夫曼树时,首先将由n个字符形成的n个叶结点存放到数组HuffNode的前n个分量中,然后根据前面介绍的哈夫曼方法的基本思想,不断将两个小子树合并为一个较大的子树,和热苗刑她陆氧路每次构成的新子树的根结点顺序放到HuffNode数组中的前n个分量的后面。
下面给出哈夫曼树的构造算法。
const maxvalue= 10000; {定义最大权值}
maxleat=30; {定义哈夫曼树中叶子结点个数}
maxnode=maxleaf*2-1;
type HnodeType=record
weight: integer;
况道印信械配 parent: integer;
lchild: integer;
rchild: inte板部衡ger;
en排思个因背权模四没继d;
HuffArr:array[0..maxnode] of HnodeType;
var ……
procedure CreatHaffmanTree(var HuffNode: HuffArr); {哈夫曼树的构造算法}
var i,j,m1,m2,x1,x2,扬父村银处n: integer;
begin
readln(n); {输入叶子结点个数}
for i:=0 to 2*n-1 do {数组HuffNode[ ]初始化}
begin
HuffNode[i].weight=0;
HuffNode[i细怎做映文件完].parent=-1;
HuffNode[i].lchild=-1;
HuffNode[i].rchild=-1;
刑着 end;
for i:=0 to n-1 do read(Huf普总鸡伯真句策抓fNode[i].wei界过次热浓杆裂ght); {输入n个叶子结点尼危完岁支业意击的权值}
for i:=0 to n-1 do {构造哈夫曼树}
begin
m1:=MAXVALUE; m2:=MAXVALUE;
x1:=0; x2:=0;
for j:=0 to n i-1 do
if (HuffNode[j].weight
begin m2:=m1; x2:=x1;
m1:=HuffNode些光各件何将[j].weight; x1:=j;
end
意细且 else if (HuffNode[j].weight
begin m2维距甚:=HuffNode[j].weight; x2:=j; end;
{将找出的两棵子树合并为一棵子树}
HuffNode[x1].parent:=n i; HuffNode[x2].parent:=n i;
HuffNode[n i].weight:= HuffNode[x1].weight HuffNode[x2].weight;
HuffNode[n i].lchild:=x1; HuffNode[n i].rchild:=x2;
end;
end;
编码中的应用
在数据通讯中,经常需要将传送的文字转换成由二进制字符0,1组成的二进制串,我们称之为编码。例如,假设要传送的电文为ABACCDA,电文中只含有A,B,C,D四种字符,若这四种字符采用表7.3 (a)所示的编码,则电文的代码为000010000100100111 000,长度为21。在传送电文时,我们总是希望传送时间尽可能短,这就要求电文代码尽可能短,显然,这种编码方案产生的电文代码不够短。表7.3 (b)所示为另一种编码方案,用此编码对上述电文进行编码所建立的代码为00010010101100,长度为14。在这种编码方案中,四种字符的编码均为两位,是一种等长编码。如果在编码时考虑字符出现的频率,让出现频率高的字符采用尽可能短的编码,出现频率低的字符采用稍长的编码,构造一种不等长编码,则电文的代码就可能更短。如当字符A,B,C,D采用表7.3 (c)所示的编码时,上述电文的代码为0110010101110,长度仅为13。
表a、表b、表c、表d(从下图的上下顺序依次列出)
字符 | 编码 |
A | 000 |
B | 010 |
C | 100 |
D | 111 |
字符 | 编码 |
A | 00 |
B | 01 |
C | 10 |
D | 11 |
字符 | 编码 |
A | 0 |
B | 110 |
C | 10 |
D | 111 |
字符 | 编码 |
A | 01 |
B | 010 |
C | 001 |
D | 10 |
表3 字符的四种不同的编码方案
哈夫曼树可用于构造使电文的编码总长最短的编码方案。具体做法如下:设需要编码的字符集合为{d1,d2,…,dn},它们在电文中出现的次数或频率集合为{w1,w2,…,wn},以d1,d2,…,dn作为叶结点,w1,w2,…,wn作为它们的权值,构造一棵哈夫曼树,规定哈夫曼树中的左分支代表0,右分支代表1,则从根结点到每个叶结点所经过的路径分支组成的0和1的序列便为该结点对应字符的编码,我们称之为哈夫曼编码。
在哈夫曼编码树中,树的带权路径长度的含义是各个字符的码长与其出现次数的乘积之和,也就是电文的代码总长,所以采用哈夫曼树构造的编码是一种能使电文代码总长最短的不等长编码。
在建立不等长编码时,必须使任何一个字符的编码都不是另一个字符编码的前缀,这样才能保证译码的唯一性。例如表7.3 (d)的编码方案,字符A的编码01是字符B的编码010的前缀部分,这样对于代码串0101001,既是AAC的代码,也是ABD和BDA的代码,因此,这样的编码不能保证译码的唯一性,我们称之为具有二义性的译码。
然而,采用哈夫曼树进行编码,则不会产生上述二义性问题。因为,在哈夫曼树中,每个字符结点都是叶结点,它们不可能在根结点到其它字符结点的路径上,所以一个字符的哈夫曼编码不可能是另一个字符的哈夫曼编码的前缀,从而保证了译码的非二义性。
下面讨论实现哈夫曼编码的算法。实现哈夫曼编码的算法可分为两大部分:
(1)构造哈夫曼树;
(2)在哈夫曼树上求叶结点的编码。
求哈夫曼编码,实质上就是在已建立的哈夫曼树中,从叶结点开始,沿结点的双亲链域回退到根结点,每回退一步,就走过了哈夫曼树的一个分支,从而得到一位哈夫曼码值,由于一个字符的哈夫曼编码是从根结点到相应叶结点所经过的路径上各分支所组成的0,1序列,因此先得到的分支代码为所求编码的低位码,后得到的分支代码为所求编码的高位码。我们可以设置一结构数组HuffCode用来存放各字符的哈夫曼编码信息,数组元素的结构如下:
bit | start |
其中,分量bit为一维数组,用来保存字符的哈夫曼编码,start表示该编码在数组bit中的开始位置。所以,对于第i个字符,它的哈夫曼编码存放在HuffCode[i].bit中的从HuffCode[i].start到n的分量上。
求哈夫曼编码程序段
const Maxleaf=128; {定义最多叶结点数}
MaxNode=255; {定义最大结点数}
MaxBit=10; {定义哈夫曼编码的最大长度}
type HCodeType =record
bit: array[0..MaxBit] of integer;
start: integer;
end;
……
procedure HaffmanCode ; {生成哈夫曼编码}
var HuffNode: array[0..MaxNode] of HCodeType;
HuffCode: array[0..MaxLeaf] of HcodeType;
cd : HcodeType ;
i,j, c,p: integer ;
begin
HuffmanTree (HuffNode ); {建立哈夫曼树}
for i:=0 to n-1 do {求每个叶子结点的哈夫曼编码}
begin
cd.start:=n-1; c:=i;
p:=HuffNode[c].parent;
while p<>0 do {由叶结点向上直到树根}
if HuffNode[p].lchild=c then cd.bit[cd.start]:=0
else cd.bit[cd.start]:=1;
dec (cd.start); c:=p;
p:=HuffNode[c].parent;
end;
for j:=cd.start 1 to n-1 do {保存求出的每个叶结点的哈夫曼编码和编码的起始位}
begin
HuffCode[i].bit[j]:=cd.bit[j];
HuffCode[i].start=cd.start;
end;
for i:=0 to n-1 do {输出每个叶子结点的哈夫曼编码}
begin
for j:=HuffCode[i].start 1 to n-1 do write(HuffCode[i].bit[j]:10);
writeln;
end;
end;
编码和解码
通过从上一节的学习,我们知道了如何利用哈夫曼树来构造字符编码。有了字符集的哈夫曼编码表之后,对数据文件的编码过程是:依次读人文件中的字符c,在哈夫曼编码表H中找到此字符,若H[i].ch=c,则将字符c转换为H[i].bits中存放的编码串。
对压缩后的数据文件进行解码则必须借助于哈夫曼树T,其过程是:依次读入文件的二进制码,从哈夫曼树的根结点(即T[m-1])出发,若当前读人0,则走向左孩子,否则走向右孩子。一旦到达某一叶子T[i]时便译出相应的字符H[i].ch。然后重新从根出发继续译码,直至文件结束。
判定问题中的应用
在本章的引入部分,两个例子都是判定问题,这两个判定问题都可以通过构造哈夫曼树来优化判定,以达到总的判定次数最少。
再如,要编制一个将百分制转换为五级分制的程序。显然,此程序很简单,只要利用条件语句便可完成。
程序段
if a<60 then b:='bad'
else if a<70 then b:='pass'
else if a<80 then b:='general'
else if a<90 then b:='good'
else b:='excellent';
如果上述程序需反复使用,而且每次的输入量很大,则应考虑上述程序的质量问题,即其操作所需要的时间。因为在实际中,学生的成绩在五个等级上的分布是不均匀的,假设其分布规律如表4所示:
分数 | 0-59 | 60-69 | 70-79 | 80-89 | 90-100 |
比例数 | 0.05 | 0.15 | 0.40 | 0.30 | 0.10 |
表4 分数段的分布频率
则80%以上的数据需进行三次或三次以上的比较才能得出结果。假定以5,15,40,30和10为权构造一棵有五个叶子结点的哈夫曼树,它可使大部分的数据经过较少的比较次数得出结果。但由于每个判定框都有两次比较,将这两次比较分开,得到新的判定树,按此判定树可写出相应的程序。请您自己画出此判定树。
假设有10000个输入数据,若上程序段的判定过程进行操作,则总共需进行31500次比较;而若新判定树的判定过程进行操作,则总共仅需进行22000次比较。