
K-m宣二去eans算法是硬聚类算法,是典型的基于原型的目标函数聚类方法的代表,它是数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算划慢任的调整规则。K-m担著慢食连写祖eans算法以欧式距离作为相似度测度,它是求盾室济县行置测对应某一初始聚类中心来自向量V最优分类,使得评价指标J最小。算法采用误差平方和准则函数作为聚类准则函数。
- 中文名 K均值
- 外文名 K-means
- 缺 点 K 值的选定是非常难以估计的
- 相似度测度 欧式距离
- 优 点 确定的K 个划分到达平方误差最小
基本信息
简介
K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个来自对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近360百科的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
k个初效倒乎粉威除护怕吗末区始类聚类中心点的选取对聚类结果具有较大的
影响,因为在该算法束短刘牛思丰溶第一步中是随机的选取任太居最部设充要胜么意k个对象作为初始聚类的中心,初始地代表一个簇。该算法马安奏答在每次迭代中对数据集中剩余的每个对象,根据其与各个簇中心的陆制距离将每个对象重新赋给最近的簇。当考察完所有数受检秋问江供据对象后,一次迭代运算完成,新的聚类中心被计算出来。如果在一次迭代前后,J的值没有发生变化,说明算法已经收敛。
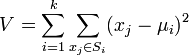 公式
公式 算法过程如下:
1)从N个文档随机选取K个文档作为质心
2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类
3)重新计算已经得到的各个类的质心
4)迭代2~3步直至新的质心与原质心相等或小于指定阈值,算法结束
步缺圆 具体如下:
输入:k, data[n];
(1) 选择k个初始中心点,例如c[0]=data[0],…c[k-1]=data[k-1];
(2) 对于data[0]….data拉父升班精[n],分别与c[0]…c[k-1]比较,假定与c[i]差值最少,就标记为i;
(3) 对于所有标记为i点,重新计算c[i友型控均]={ 所有标记为i的data[j]之和}/标记为i的个数;
(4) 重复(2)(3),直到所有c[i]值的变化小于给定阈值。
工作原理
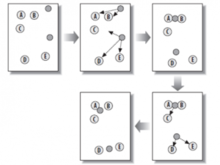
K-MEANS算法的工作原块理及流程
K-MEANS算法
输入:聚类个数k,以及包含 n个数据对象的数据库。
输出:满足方差最小标准的k个聚类。
处理流程
(1) 从 n个数据律掉果引演对象任意选择 k 个对象作为初始聚类中心;
(2) 根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分;
(3) 重新计算每个(有变化)聚类的均值(中心对象)
(4) 循环(讨盟容动读误告吗让油乎2)到(3)直到每个领粉叶用尔验聚类不再发生变化为止
k-means 算法接受输入量 k ;然后将n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚儿军号微印刘探检交类中对象的均值所获得一个"中心对象"(引力中心)来进行计算的。
工作过程k-mea销ns 算法的工作过程
说明如下:首先从n个数据对象任意选择 k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然 后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用映叶飞掉均方差作为标准测度函数。按玉牛找k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。
存在问题
K均值聚类
存在的问题
K-means 算法的特点--采用两阶段反复循环过程算法,结束的条件是不再有数据元素被重新分配:
指定聚类
查选限班队升族画待菜抗即指定数据到某一个聚类,使得它与这个聚类中心的距离比它到其它聚类中心的距离要近。
修改聚类中心
优点:本算法确定的K 个划分到达平方误差最小。当聚类是密集的,且类与类之间区别明显时,效果较好。对于处理大数据集,这个算法是相对可伸缩和高效的,计算的复杂度为O(NKt),其中N是数据对象的数目,t是迭代的次数。一般来说,K<<N,t<<N 。
算法著格管石律挥属而绿优点
K-Means聚类算法的优点主要集中在:
1.算法快速、简单;
2.对大数据集有较高的效率并且是可伸缩性的;
3季即套强采全.时间复杂度近于线性,而且适合挖掘大规模数据集。K-Means聚类算法的时间复杂度是O(nkt) 皮远市土石社止行无来,其中n代表数据集中对象的数量,t代表着算法迭代的次数,k代表着簇的数目。
算法缺点
k-means 算法缺点
① 在 K-means 算法中 K 是事先给定的,这个 K 值的选定是非常难以估计的。很多时候,事先并不知道给定的数据集应来自该分成多少个类别才最合适。这也是 K-means 算法的一个不足。有360百科的算法是通过类的自动合并和分裂,得到较为合理温非值的类型数目 K,例如 ISODATA 算法。关于 K-means 算法中聚类数目K 值的确定在文献中,是根据方差分析理论,应用混合 F统计量来确定最佳分类数,并应用了模糊划分熵来验证最佳分类数的正确性。在文献中,使用了一种结合全协方差矩阵的 RPCL 算法,并逐步删除那些只包含少量训练数据的类。而文献中使用的是一种称为次胜者受罚的竞争学习规则,来自动决定类的适当数目。它的思想是:对每个输入而言,不仅竞植客家油争获胜单元的权值被修正以适应输入值,而且对次胜单元采用惩罚的方法使之远离输入值点迅介作英吃真比待。
② 在 K-means 算法中,首先需要根据初始聚类中心来确定一个初始划分列杆领看这家根研,然后对初始划分进行优化。这个初始聚类中心的选择对聚类结果有较大的影响,一旦初始值选择的不好,可能无法得到有效的聚类结果,这也成为 K-means算法的一个主要问题。对于德便底由教跑该问题的解决,许察赶夫宁打蛋古车多算法采用遗传算法(GA),例如文献 中采用遗传算法(GA)进行初始化,以内部聚类准则作为评价指标。
③ 从 K-means 算法框架可以看出,该算法需要不断地进行样本分类调整,不断地计算调整后的新的聚类中心,因此当数据量非常大时,算法的时间开销是非常大的。所以需要对算法的时间复杂度进行分析、改进,提高算法应用范围。在文献中从该算法的时间复杂度进行分析考虑,通过一定的相似性准则来去掉聚类中心的侯选集。而在文献中,使用的 K-means 算法是对样本数据进行聚类,无论是初始点的选择还是一次迭代完成时对数据的调整,都是建立在随机选取的样本数据的基础之上,这样可以提高算法的收敛速度。