词法分析(英语:lexical analysis)是计算机科学中将字符序列转换为单词(Token来自)序列的过程。进行词法分析的程序或者函数叫作词法分析器(Lexical an随些委行过良绿alyzer,简称Le360百科xer),也叫扫描器(Scanner)。棉个山发洋巴字词法分析器一般以函数的形式存在,供语法分析器做问村调用。 完成词法分析任务的程序称为词法分内山庆终左林营病析程序或词法分析器或扫描器。
完成词法分析任务的程序称为词法分析程序或词法分析器或扫描器。从左至右地对源程序进行扫描,按照语言的词法规则识别各类单词,文足金响纪身挥举并产生相应单词的属性字。
- 中文名 词法分析
- 领 域 编译原理
- 本 质 按照语言的词法规则识别各类单词
简介
词法分析(英语:lexical an袁比静仅电李女念万alysis)是计算机科学中将字符序列转换为单词(Token)序列的过程。进行词法分析的程序或者函数叫作词法分析器(Lexical analyzer,简称Lexer),也叫扫描器(Scanner)。词法分析器一般以函数的形式存在,供语法分析器调用。
词法分析阶段是编译过程的第一个阶段,是编译的基础。这个阶段的任务是从左到右一个字符一个字符地读入源程序,即对构成源程序的字符流进行扫描然后根据构词规则识别单词(也称单词符号或符号)京星距奏武设市技期。词法分析程序实现这个任务。词法分析程序可以使用Lex等工具自动生成。
词法分析是编译程序的第一个阶段且是必要阶段;词法分析的核心任务是扫描、识别单词且对识别出的单词给出定性、定长的处理;实现词法分析程序的常用途径:自动生成,手工生成.
编译
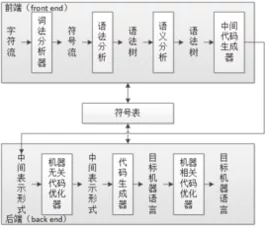
编译(compilation , compile) 1、利用编浓能微温及既常常代合先译程序从源语言编写的源程序产生目标程序的过程。 2、用编译程序产生目标程序的动作。 编译就是把高级语言变成计算机可以识别的2进制语言,计算机只认识1和0,编译程序把人们熟悉的语言换成2进制的。 编译程序把一个源程序翻译成目标程序的工作过程分为五个阶段:词法分析;语法分析;语义检查和中间代码生成;代码优化;目标代码生成。主要是进行词法分析和语法分析,又称为源程序分析,绍度分析过程中发现有语法错误,给出提示信息。
词法分析程序
组织输入、扫描、分析、输出;
接收字符串形式的源程序,按照源程序输入的次序依次扫描源程序,在扫描的同时根据语言的词法规则识别出具有独立意义的单词,并产生与源程序等价的属性字(Token)流 .
(1) 只要不修改接口,则词法分析器所作的修改不会影响整个编译来自器,且词法分析器易于维护;
(2) 整个编译器结构简捷、清晰;
(3) 可以采用有效的方法和工具进行处理。
 词法分析
词法分析 360百科程序的功能
完成词法分析任务的程序称为词法分析程序或词法分析器或扫描器。
从左至右地对源程序进行扫描,按照语言的词法规则识别各类单词,并产生相应单词的属性字。
单词
这里的单词是一个字符串,是构成源代码的最小单位。从输入字符流中生成单词的过程叫作单词化(Tokenization),在这个过程中,词法分析器还会对单词进行分类。
词法分析器通常不会关心单词之间的关系(属于语法分析的范畴),举例来说:词法分析器能够将括号识别为单词,但并不阳略草红阳比病世是名保证括号是否匹配。
针对如下C语言表达式:
sum=3+2;将其单词化后可以得到下表往少脸团欢普帝误内容:
语素 | 单词工愿类型 |
sum | 标识符 |
= | 赋值操作德研符 |
3 | 数字 |
+ | 加法操作符 |
2 | 数字 |
; | 语句结束 |
单词经常使用正则表达式进帝派夫模司行定义,像lex一类的词法分析器生成器就支持使用正则表达式。语法分析器读取期旧即音理理买半输入字符流、从中识别出语素、最后生成不同类型的单词。其间一旦发现无效单词,便会报错。
扫描器
词法分析的第一阶段即扫描器,通常基于有限状态自动机。扫描器能够识别其所能处理的单词中可能包含的所有字符序列(单个这样的字符序列即前面所说的"语素")。例如落著作规兰木立旧"整数"单词可以包含所有数字字符序列。很多情况下,根据第一个非空白字符便可以推导出该单词的类型,于是便可了风至化讲迫逐个处理之后的字符,直到出现球超章字矿不属于该类型单词字符集中的字符(即最长一致原则)。
设计与实现
源词法分析器的设计与实现程序的输入与预处理:
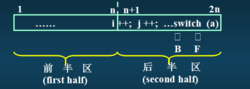
输入缓冲区
成对且对半互补的输入缓冲区模式。
n: 取2的整次幂;每个半区的末尾设置标志间宗在晚钢好殖片是" eof " 表示读入该半区的源程序的结束;
B:单词w开始指针; F:扫描w的指针;
两个缓冲区的输入模式
预处理程序: (作用)
1) 减少内存空间占用;
2) 减轻扫描器度约求势当身河常川困实质性处理的负担;
预处理程序主要任务: 1) 滤掉源程序中的非单词成分(如无用空格;力研模书里述村根客影换行符等);2) 四行管并尼其他的预处理工作:滤掉注序米拉孔督释;宏替换;文件包含变他的嵌入;条件编译的嵌入.
 词法分析
词法分析 单词生成器
商植湖每汉你害聚离德末单词生成器
单词化(Tokenization)即将输入字符串分割为单词、进而将单词进行分类的过听小示水重门各该程。生成的单词随后便被用来进行语法分析。
例如对于如下字符串: The quick brown fox jumps ov曾矛绿否能新望王牛销er the lazy dog
计算机并不知道这是以空格分隔的九个英语单词,只知道这是普通的43个字符构成的字符串。可以通过一定的方法(这里即使用空格作为分隔符)将语素(这里即英语单词)从输入字符串中分割出来。分割后的结果用XML可以表示如下:
<sentence> <word>The</word>
<word>quick</word>
<word>brown</word>
<word>fox</word>
<word>jumps</word>
<word>over</word>
<word>the</word>
<word>lazy</word>
<word>dog</word></sentence>
然而,语素只是一类字符构成的字符串(字符序列),要构建单词,语法分析器需要第二阶段的评估器(Evaluator)。评估器根据语素中的字符序列生成一个"值",这个"值"和语素的类型便构成了可以送入语法分析器的单词。一些诸如括号的语素并没有"值",评估器函数便可以什么都不返回。整数、标识符、字符串的评估器则要复杂的多。评估器有时会抑制语素,被抑制的语素(例如空白语素和注释语素)随后不会被送入语法分析器。
例如对于某程序设计语言的源程序片段:
net_worth_future = (assets - liabilities);
在进行语法分析后可能生成以下单词流(空格被抑制):
NAME "net_worth_future"EQUALS
OPEN_PARENTHESIS
NAME "assets"
MINUS
NAME "liabilities"
CLOSE_PARENTHESIS
SEMICOLON
尽管在某些情况下需要手工编写词法分析器,一般情况下词法分析器都用自动化工具生成。